Do You Really Know Git?
In all seriousness, git is one of the tools everybody has to work with, and understanding how it really works is going to make your life so much easier in the long run.
What you might not realize is that there are just a handful of git concepts you have to master, and then everything will fall into place. So… without further ado, let’s open the terminal and see git in action.
1. Git Basics
Let’s start by creating a new folder, and an index.js file where we are printing something in the console.
$ mkdir awesome-git
$ vim index.js
console,log("Hi, Awesome!");
~
~
~
~
~
:wq
This ain’t much, but I’m an optimist so I can already see this project becoming a multi million dollar startup.
As a result I want to make sure my work here is not lost, and that all the great developers who will join my venture can collaborate on future features. This is where Git comes into play.
With the “git init” command we can initialize an empty repository, which creates a special .git hidden directory in your project. The chances are you’ll never have to look inside this folder, but just keep in mind that this is the place where git stores all the information and data necessary for managing your repository.
Unlike other version control systems that store data as a list of file-based changes, Git stores data as a series of snapshots of the entire project. When you commit changes in Git, it saves a snapshot of all your files at that point in time.
The most important thing you need to understand about working with git is that there are 4 main areas where your code can reside.
First, any newly created or modified file will be placed in the working directory. This is where all your work happens, and changes in the working directory are not tracked by Git until you add them to the staging area.
So let’s use “git add” to stage our index.js file.
$ git add index.js
The staging area, also known as the Index, is where you can prepare changes before committing them to the local repository.
You can then use the “git status” to see a list of changes ready to be committed.
$ git add index.js
$ git status
The status command shows the state of both the working directory and the staging area, so if we add a new config.properties file, and run the command again, you’ll see that the newly created file is part of your working directory, but is not yet tracked by Git.
$ echo ACCESS_KEY=hgn6hs > config.properties
$ git status
Since property files might contain access keys and sensitive information not suited for other developers you might not want to make this available in the repository. The best way to accomplish that is via .gitignore where you can specify files or directories to be excluded from the index.
$ echo ACCESS_KEY=hgn6hs > config.properties
$ git status
$ echo config.properties > .gitignore
Now, if I run “git status” again the config file is not showing up, so it will stay saved only on my local device.
The third Git area is the local repository. This is where the project history is stored. With the “git commit” command we can move the files from the staging area into the local repository.
$ git commit -m "initial commits"
Each commit represents a snapshot of your project at a specific point in time, and you can use the -m flag to provide a description associated with the changes you are committing to the repo.
So, at this point, if you run “git status” you’ll see that your staging area is empty because your changes were just committed, and if you run “git log” you’ll see your first commit into the local repository.
$ git log
Git will maintain a history of all your commits, and each commit has an associated hash, which is a unique identifier we can use to jump back in time to see older versions of our project. The log also shows a HEAD pointer, which indicates your current position in the repository. This usually points to the last commit, but can be “detached” if we are going back in time.
To see this in action, let’s first make a small change to our index.js file, stage the changes, and add a second commit into our local repository.
$ vim index.js
$ git add .
$ git commit -m "update greeting"
With “git log —oneline” we can see a compact view of our commit history.
$ vim index.js
$ git add .
$ git commit -m "update greeting"
$ git log --oneline
The HEAD points to the last commit, but we can now use the “git checkout” command to go back in time before we updated the greeting.
$ vim index.js
$ git add .
$ git commit -m "update greeting"
$ git log --oneline
$ git checkout 3d86522
You can now see the older version of your file, which can be very useful in real world projects. We are also notified that we are in a “detached HEAD” state. We can explore and make changes, but these changes won’t belong to any branch unless you explicitly create a new branch from this state. Branches are the bread and butter of Git, and we’ll discuss them in detail in a second. For now just remember that all this work is done on the default, main branch. Let’s run “git switch -” to go back to the top of our history.
By the way, you can compare any two commits to understand the changes between them using the “git diff” command.
$ git diff 3d86522 8419d17
Ok, we made quite a lot of progress but note one important aspect - we are still in the 3rd Git area - the local repository.
One of the main benefits of Git is code collaboration, and, in order to do this we need to host our repository on the internet or on a private network into a remote repository. There are various popular platforms which can host your repository, and we’ll work with GitHub in this article.
You can easily create a repository through their web app, and you’ll end up with a URL such as this one.
$ git remote add origin https://github.com/awesome/awesome-git.git
Then we can register this URL as the main remote to our repository, and we should be good to go.
We now can finally move all our code and change history into the 4th area using the git push command.
$ git remote add origin https://github.com/awesome/awesome-git.git
$ git push --set-upstream origin main
Quick side note, I know I said there are only 4 areas where git files can be present, but, technically there is a 5th place called the stash. Running “git stash” will move your uncommitted files into this special area, so that your working tree is clean again. This comes in handy when you need to merge or work on a hot fix but you don’t want to commit the existing changes just yet. The files can be brought back into the working tree via the stash pop command.
2. Collaboration
Ok, now let’s imagine your project is actually gaining traction, and you are bringing a second developer in your team.
The first thing they’ll do is to create a copy of the remote repository using the clone command.
$ git clone https://github.com/awesome/awesome-git.git
Then they can go through the same process we already described.
They would open the index file, make another change to it, stage the changes, commit them to the local repository and then push it to the remote.
$ vim index.js
$ git add .
$ git commit -m "Bad luck commit"
$ git push
Now you can use “git fetch” to bring those new changes from the remote inside your local repo.
$ git fetch
Note that fetch will only bring in the changes in the 3rd area, which means you don’t have the updated index.js file in your working directory. This gives you the chance to inspect the incoming changes using “git log” or merge those changes into your current branch using “git merge”.
$ git merge
Usually, in real world scenarios, fetch and merge will go hand in hand, so you can conveniently use “git pull” to do both steps at once. If everything goes well, and there are no conflicting changes, your branch is fast forwarded which means that the code will be moved from the remote repo, to your local repo and then in the working directory as well. Things get a bit more complicated when multiple branches and conflicts are involved, so let’s look into some more advanced scenarios next.
3. Branches
Up until this point we only worked on the main branch, which might be fine for small teams and projects. However, the real power of Git resides in its branch feature. In short, branches allow multiple versions of a repository to exist at the same time.
If some new functionality has to be implemented, it is always a good idea to do so on a feature branch. This allows the programmer to have a separate development and testing cycle on that branch, while the rest of the team can continue other development efforts in parallel, either on different feature branches or directly on the main branch.
In our example, we can create a new branch using the “git branch” command followed by the new branch name.
$ git branch feature
Using the command without the name will show a list of your local branches, including the branch you are currently on.
$ git branch
With the same “git checkout” command we used earlier to view past commits, we can also switch to the newly created branch.
$ git checkout feature
At this point, this version is a replica of the main branch. Let’s add a few more lines inside our index.js, and then commit the changes in the local repo.
$ vim index.js
$ git commit -am "Added sum function"
Note that I’m using the “a” flag as well, to automatically stage all files before committing.
Now, we can push this new branch to the remote repo, and we have to use the “—set-upstream” flag to associate a remote branch to our newly created local one.
$ vim index.js
$ git commit -am "Added sum function"
$ git push --set-upstream origin feature
Switching to another developer perspective which doesn’t have these changes locally, you’ll see a “new branch” message when executing “git fetch”.
$ git fetch
Again, fetch only brings in the changes in the local repository, and we can run “git merge feature” to add the changes from the feature branch in the main branch.
$ git fetch
$ git merge origin/feature
Here is an interesting question. At this point in time, are the changes from the remote feature branch also on the remote main branch? The correct answer is no. When we merged the feature branch into main, this was done in the 3rd area, meaning only locally. We still need to do a “git push” to have these newly merged changes on the remote main branch as well.
4. Conflicts
Up until this point we kept things simple, but working with git has way more nuances in the real world.
When collaborating on multiple branches, the straight forward scenario is the following.
- When a new feature request comes in, a feature branch which will diverge from the main branch is created.
- When merging “feature” back into “main” if there are no additional commits added on the main branch since the branch off, the “feature”commits are simply moved to the main branch as well.
However, more often than not, additional work might be added on “main” during this time. In this case, git will use a strategy called three-way merge to determine how to combine the changes from the two branches.
The process involves three commits: the two branch tips, and the most recent common commit from which both tips have diverged.
In other words, git will compare and find the list of differences between the current branches’ snapshots and the last common point. The idea is to combine and then apply these changes after the last common commit, so that we end up with all the changes in one place on the main branch.
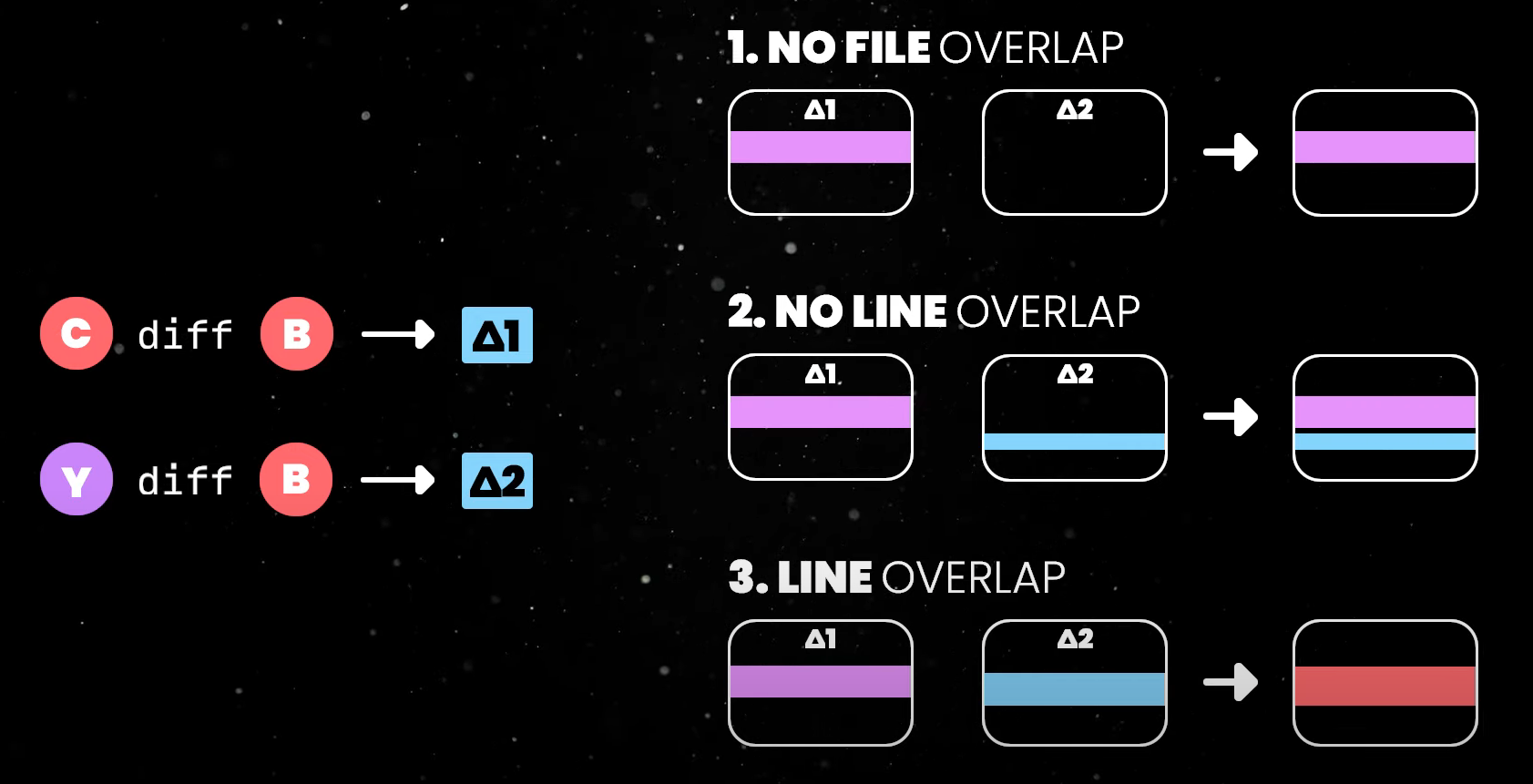
There are 3 possible scenarios.
-
These changes could be in separate files. In this case, applying them is straightforward since there is no code overlapping.
-
If the changes are targeting the same file, but the changed lines are different, again, we could just update the file in a straightforward manner.
-
When both branches have changes targeting the same file and the same lines, the merge cannot be performed automatically, and you have to manually jump into these files and resolve the conflicts.
It’s important to know that this merge process will be solved via a merge commit, which will show up in your git history. This is not really problematic, but, in practice, having a linear history makes it easier to understand your project.
Squash Merge
We could solve this via a squash merge, which combines the changes from the feature branch by basically combining all commits into a single commit which will be applied on main. With this option your history is linear, but you lose the commit history of the feature branch. This might be important when debugging later.
Rebase & Cherry-Pick
The better option then is to do a rebase, where your commits from the feature branch are sequentially reapplied on the main branch. Git does this internally through a process similar to cherry-picking, which is a powerful command that allows you to move specific commits between branches.
$ git cherry-pick avc1234
Of course, if any conflicts arise during the rebase process, Git will pause and prompt you to resolve them.
If you feel like you learned something, you’ll probably find some of these videos interesting as well.
Until next time, thank you for reading!