The Right Way To Build REST APIs
It goes without saying that knowing how to build performant, quality REST services is a prerequisite for anybody involved in Web Development.
Yes, this is true for both backend and frontend developers. After all, both parties are responsible for this communication to run smoothly. The client sends in HTTP requests to a specific Server URL, using one of the many HTTP verbs, and appending information either via headers, query params or the request body.
POST /api/data HTTP/1.1
Host: www.awesome.club/posts
Content-Type: application/json
User-Agent: Mozilla/5.0 (Macintosh; Intel) ...
Accept: application/json
Content-Length: 47
Connection: keep-alive
{
"id": "xha99s8sj",
"title": "Build REST APIS",
}
In return the server will process that request, and will send back to the client a response with a Status code and information stored in response headers and body.
HTTP/1.1 200 OK Date: Mon, 26 Jun 2024 12:00:00 GMT Server: Apache/2.4.18
(Ubuntu) Last-Modified: Wed, 22 Jun 2024 19:15:56 GMT Content-Type: text/html;
charset=UTF-8 Content-Length: 140 Connection: close
<!doctype html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<p>HTML returned as an HTTP response.</p>
</body>
</html>
What you might not realize is that building a professional REST API is easier than you would think. All you need to do is learn a few key concepts and best practices.
So let’s start this by quickly assessing an example. In system design only one of these URLs is considered correct.
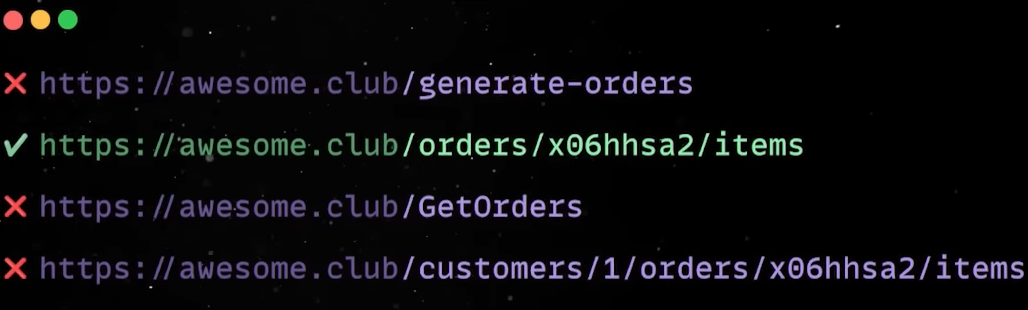
Do you know which one? Do you know why?
1. REST Maturity Model
Roy Fielding introduced the Representational State Transfer, also known as the REST model back in the year 2000 in an attempt to improve the scalability and performance of network-based software systems through a set of sensible architectural principles. In the meantime, this model has become the industry standard for building modern web applications and services.
We’ll look at these principles in detail in a second, but for now just remember that there are different stages of maturity in designing a REST API. This maturity model was introduced by Leonard Richardson, and outlines four levels, ranging from the most basic Level 0, where HTTP is used simply as a transport mechanism for exchanging messages, to the most advanced Level 3, where services not only use resource URIs and HTTP methods but also includes hypermedia links to guide clients on how to interact with the service dynamically. On this scale, services should move towards a resource-oriented approach (Level 1) where the HTTP protocol is fully utilized(Level 2).

1. Stateless
REST APIs should be stateless. In a distributed environment, “stateless” means client requests aren’t tied to a specific server .Servers don’t keep session states, allowing clients to interact with any server in a load-balanced manner.
In a single server setup, “stateless” means the server can handle requests without any knowledge of previous requests from a certain client. This makes your API scalable and available. Any server can handle any request, so if one server crashes, another one picks up the slack without missing a beat.
On top of that, stateless APIs are easier to cache and optimize since the same response can be returned for identical requests.
However, more often than not, we need to store state associated with the user actions. The most common example is a shopping cart, where the client can add, remove or modify items as they navigate the site. Even with this constraint, our services can still be stateless as long as two main rules are followed.
- First of all the state has to be stored externally, either in a database or in some sort of memory cache. This makes sure that the app does not rely on any internal state, and it can operate independently.
- Second, some sort of identification like a JWT token has to be associated with each user, so that any subsequent request can be correctly mapped to the correct shopping cart entity.
So, since servers do not maintain client context, each request sent from the client must contain all information necessary to process the request.
I mentioned JSON web tokens, so this is a good time to take a 30 seconds detour into securing your APIs.
Of course, your services should follow all the best practices when it comes to security. Believe me, I know security is not an appealing topic for most of us, but there are a few basic rules everybody should know and follow.
First, all communication should happen over a secure protocol. While HTTP transmits data over the internet in plain text, HTTPS uses a cryptographic protocol to ensure that the client and server are exchanging data over a secure channel that protects against man-in-the middle attacks.
Second, some sort of token-based authentication has to be employed, and JWT tokens are somewhat of an industry standard on this front. Of course, there are a couple of strict rules you need to follow:
- Your tokens have to be securely stored on the client side, so that they can’t be compromised via cross site scripting or cross site request forgery attacks;
- You should implement token expiration and renewal policies to limit the duration of potential exposure to a compromise token;
- And, finally, tokens have to be rigorously validated on the server.
3. Endpoints
Ok, moving to more concrete topics, let’s look at our rest endpoints. REST enforces a strict separation of concerns between the client and the server, and these endpoints are the channel of communication.
Good API design is organized around resources, not actions or verbs. For instance, endpoints like “create-order” should always be avoided since the create part will be redundant if we correctly use HTTP verbs.
Let’s look at an endpoint that doesn’t follow the best practices, and review 5 rules you need to follow when designing your API.
This is a URI you are likely to find in the wild, which allows browsers to retrieve the items in a specific order.

-
First, a trailing forward slash should not be included in URIs. This is one of the most important rules to follow as the last character within a URI’s path adds no semantic value and may cause confusion.
-
Second, the forward slash separator must be used to indicate a hierarchical relationship. In our case, there is a hierarchy between orders and items, so we should refactor our endpoint like this /api/order/123/GetActiveItems. With this change we can also capture the order id as a path variable instead of a query parameter.
-
Next, we should use hyphens to make it easier for people to scan and interpret our endpoints /api/order/123/get-active-items.
-
Then, as I already mentioned, we should focus on resources, not actions, so the “get” verb should be removed from the URI /api/order/123/active-items.
-
Finally, to keep things simple and uniform, always use plural names. With this we provide consistency between different endpoints. /api/orders/123/active-items
As a bonus point, remember that you want to avoid complex endpoints, so try not to use hierarchical structures with more than 2 levels. Of course, in our case the order could be linked to a customer, and that customer could be linked to a store /api/customer/2/store/32/orders/123/active-items . However, there is

So this is the final result. Of course, following this principle we can add endpoints for various other operations and relationships. Remember that at a high level, HTTP verbs map to CRUD operations in a database.
4. Responses
Ok.. but what about API responses? A rule of thumb is to never return plain text.
When a client application receives unstructured plain text, it must parse and process this data to extract necessary information, introducing potential errors and inefficiencies.
Structured media types like JSON, XML, or YAML are preferable for data representation and transmission.
JSON is ideal for rest APIs due to its simplicity, efficiency and broad support across modern web frameworks. XML, though well-supported, tends to be verbose, leading to larger file sizes and slower processing. YAML, while expressive and concise, lacks the compatibility and support that JSON offers .
Structured data formats allow for more sophisticated error reporting and handling, which brings us to the next point.
5. Exceptions
When developing software, it’s always important to have solid error handling to prevent exceptions that could propagate to the client.
The HTTP protocol offers a full range of response numerical codes to describe the outcome of the requests. They are essential in facilitating communication between clients and servers by providing a quick indication of the request’s result.
So you should always start from here.
As an example, there are multiple situations when the code could break on the server. The easiest way to handle all these is to return a 500 Internal Server Error code. However, if your error handling is properly thought out you should be able to send a 404 when the client tries to access some information that doesn’t exist on the server, or a 403 Forbidden code if the client is trying to access the order details of another customer.
6. Versioning
If you want to ruin any developer’s day, just tell them that the API they are using is going to change. Any update in the API design can have big ripple effects in the codebase.
So, developers usually work under the assumption that the API will remain stable and predictable, but, in the real world, code becomes deprecated, functionality changes and APIs will be updated.
The easiest way to handle such scenarios is via versioning, with a distinct version number added either in the URI or as a query parameter. These approaches come with the additional benefit of being cache-friendly.
However, it is worth noting that some REST purists believe that URLs should not be different depending on the version when fetching the same data. If you are one of those guys, you have the option to specify the version using a Custom or an Accept header.
7. HATEOAS (Hypermedia As The Engine Of Application State)
Ok, so all this theory and talk about best practices but, believe it or not, we are still at the second level of maturity. For your API to reach its final form, it needs to follow the “Hypermedia as the Engine of Application State” principle.
This means that the client interacts with a network application entirely through hypermedia provided dynamically by application servers. So a REST client needs no prior knowledge about how to interact with any particular application or server beyond a generic understanding of hypermedia.
In a practical example, the server response contains not only the requested data but also hypermedia links to related actions.
"order": {
"id": "g21jho9",
"total": "209.11",
"currency": "USD",
"createdDate": 1720268512481
},
"_links": {
"self": {
"href": "/api/orders/g21jho9"
},
"items": {
"href": "/api/orders/g21jho9/items"
},
"details": {
"href": "/api/orders/g21jho9/details"
}
}
So besides the requested order details, we learn how to interact with other associated resources.
This provides a discoverable and self-descriptive API, which allows the server to change URIs without breaking clients. However, this principle comes with some major disadvantages.
First of all, there is a performance cost especially for APIs with many requests for the same response.
On top of that, there is no widely accepted standard for implementing it, and, all in all, it has a fairly low adoption rate.
If you feel like you learned something, you should watch some of my youtube videos or subscribe to the newsletter.
Until next time, thank you for reading!